
















The Covalent Network Data pipeline
The goal of this page is to provide a high-level overview of the Covalent Network data pipeline.
A lot happens between blockchain data being extracted and indexed to a developer querying the unified Covalent API. With the Covalent Network, each of the steps - starting with the production of Block Specimens - will be responsibility of Network Operators, each of which is a node on the Covalent Network.
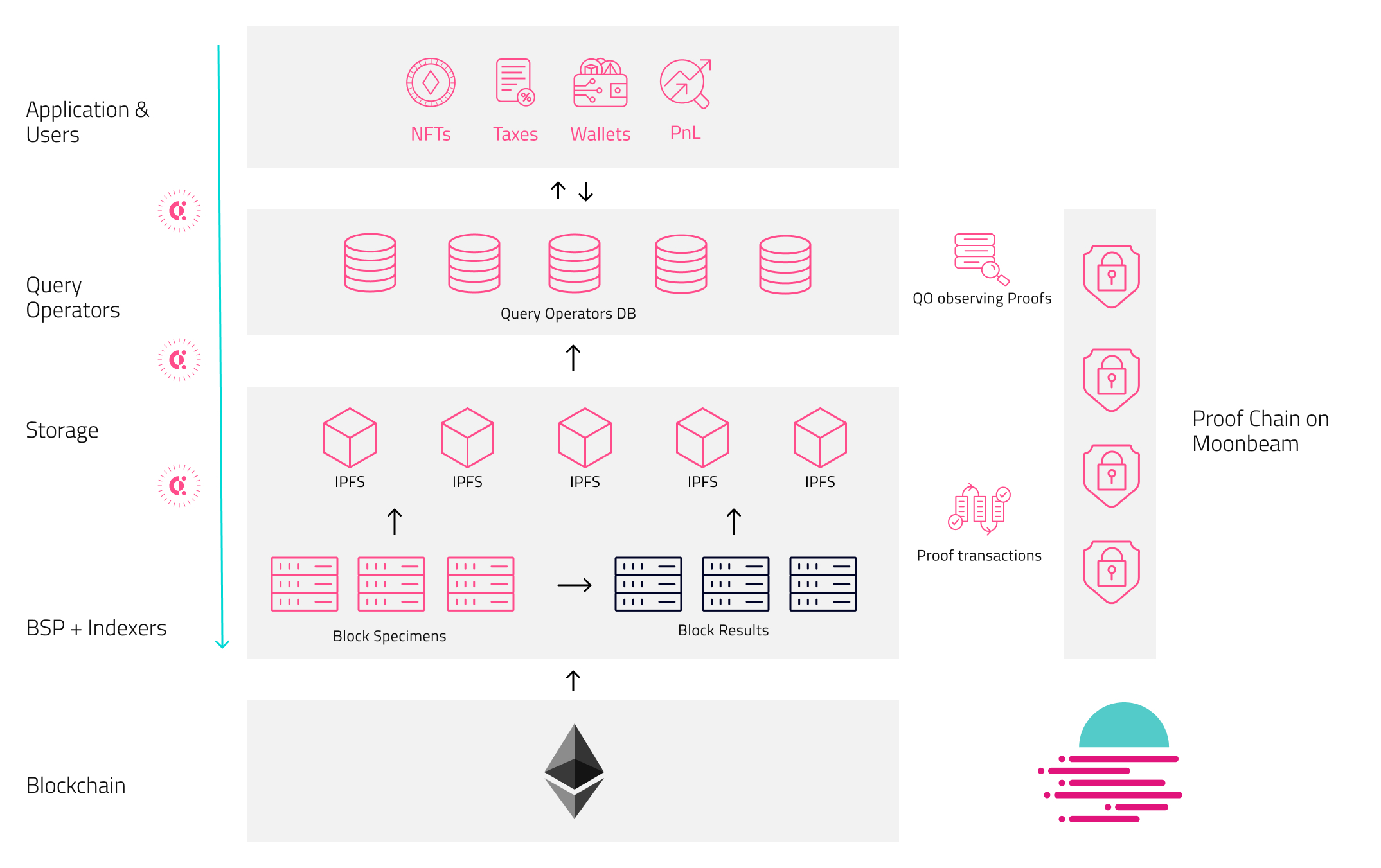
This page breaks down the Covalent Network data pipeline, from extraction to returning API queries as well as the specific Network Operators involved in each step. Given that Ethereum will be the first of many networks supported on the Covalent Network, that is the blockchain referenced in this document. The development and rollout of the Covalent Network also follows this sequence of steps.
Extract & Prove
The first phase of the pipeline involves extracting raw Ethereum data and cryptographically proving this work was done honestly. The data object created from extracting this data is called the Block Specimen. Network Operators who perform this role are referenced as Block Specimen Producers. Doing so involves running the Block Specimen specification which is patch sitting on top of existing blockchain clients like Geth and Erigon.
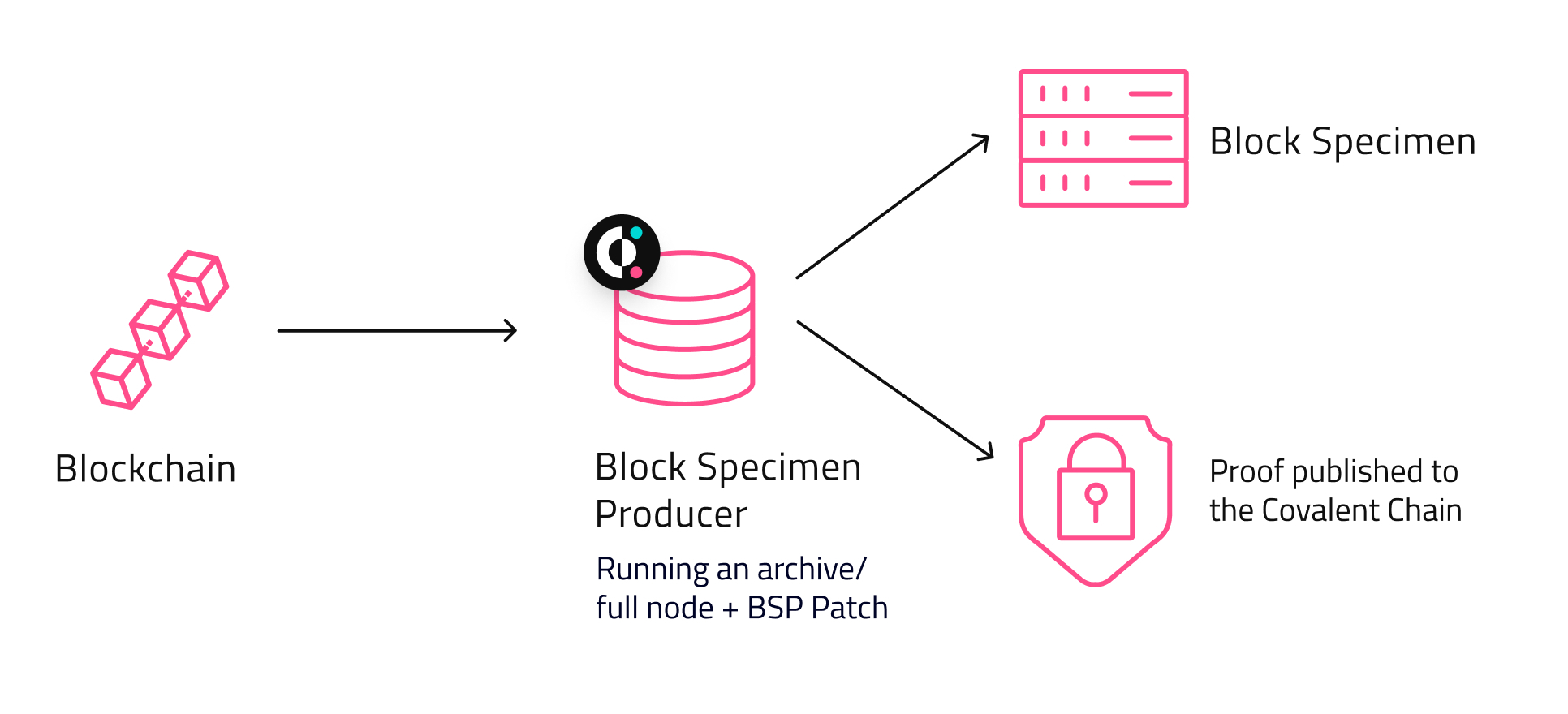
A Block Specimen can be thought of as a block and its constituent elements. For every block mined on Ethereum, a respective Block Specimen is created.
Once created, the Block Specimen is uploaded to a storage instance. The BSP will then announce to the network, via a proof, that they uploaded the Block Specimen — which is just the hash of the Block Specimen in storage where other nodes can access it to validate the proof. The proof is published to the Proof Contract which is nothing more than a smart contract to record these proofs living on MoonBeam.
By comparing proofs, one can detect any deviations in the data, either accidentally or malicious.
Transform & Audit
While a Block Specimen contains a block’s data and its constituent elements, the data remains ‘unorganised’ in this state. To make the data in the Block Specimen queryable, it must be indexed. Hence, it is transformed into a Block Result, where the data is flattened into a schema that the Covalent database expects. Indexers assume this role; pulling a Block Specimen from storage and transforming it into a Block Result. Similar to a BSP, Refiners will publish a proof to validate this work.
Auditing Proofs
As mentioned, when a Block Specimen is created, a production proof is created and published to the Covalent proof contract. As there will be multiple BSPs, a number of scenarios can arise:
-
- Every proof matches and thus every BSP has produced the same Block Specimen.
-
- Some proofs mismatch but there is a majority that match.
-
- There are no matching proofs.
To determine what scenario has transpired and who should be rewarded per epoch, a check is done off-chain (initially by Covalent). Critical to this check is the role of the auditor which is to examine an epoch of proofs, be it historic or present. Rewards are not calculated or generated until the auditors approve or falsify a given quorum was attained by the independent distinct set of operators. To communicate this, the auditor(s) messages the Covalent proof contract.
Auditors are selected at random from a base pool of operators in which they play only the role of an auditor for that epoch. For every audit that passes they’re awarded the staking block rewards of the operator for which they successfully provide the malfeasance proof. They resubmit the proof for every block and at the end of every epoch, the operators that are found to have invalid proofs are slashed accordingly.
Note:
- Until this function is developed, Covalent will be acting as the source of truth given that Covalent will be producing valid Block Specimens and publishing their respective proofs. Thus, proofs that BSPs publish can be compared against Covalent’s own. This also mitigates against the risk of collusion occurring between Operators.
- Slashing will not be live initially on the Covalent Network. Rather, if there is an invalid proof, no reward will be distributed for that epoch.
Trace & Decode
The primary output of this stage of the Covalent Network is Block Trace Results. These differ from the aforementioned Block Results in that they contain decoded contract states. This object contains an event stream consisting of both low-level, operational trace-events, and also higher-level, semantic state changes to the contracts and accounts, each annotated with the execution context they appeared in. Block Trace Results are, however, still built from Block Specimens.
Store & Serve
Up to this point, all of the work that has been completed gets announced via production proofs, whether it be a BSP producing a Block Specimen, or a Refiner creating a Block Trace Result. Furthermore, operators that produce data objects will upload them to a storage instance and make them available via a data routing protocol such as IPFS.
Query Operators will observe these events while running a local data warehouse. Skimming through the on-chain announcements, the query operators will pull data objects from storage that most interest them (based on API user demand), load them into their local data warehouse and index such. Query operators can begin to return user API queries and will be compensated in CQT for doing so.
To fetch data from the network, query operators will have to pay, in CQT, into a “network fund”. How much they have to pay is proportionate to the amount of data they’ve fetched from the network. This fund pays out in turn to the production operators such as BSP and Refiners, as network rewards.
A Note on Storage
As mentioned, operators that produce data such as BSPs will be pushing such to a storage instance. They can run this storage instance locally or make use of Storage Operators. Storage Operators are expected to observe proofs, fetch them through IPFS, and store them into their own node, to increase the availability of that data. The Storage Operator can charge the BSP for doing so.
In Sum
Block Specimens are the first data object created by Block Specimen Producers. Indexers take these and transform them into Block Results which will eventually evolve to support decoded contract states (Block Trace Results). While observing on-chain announcements made by both of these operators, Query operators load data into their local data warehouses from the storage instance used by BSP and Refiners. Query Operators are then able to respond to API queries.
While the Covalent Network will only support Ethereum initially, multiple chains will be rolled out onto the Covalent Network gradually, most likely based on demand and community involvement. Covalent meanwhile will continue to provide data for the 26+ blockchains currently supported until the Covalent Network can manage demand.